
Azure Data Factory jest usługą działającą w chmurze, pozwalającą na pobieranie danych z wielu źródeł, ich transformację oraz import do miejsca docelowego. Cały proces może zostać wykreowany za pomocą graficznego interfejsu w Azure Data Factory Studio.
Poniżej przedstawionych zostanie kilka działań, które powinny zostać podjęte, aby utworzyć podstawowy proces ETL. Przyjmijmy, że bazowe warunki dla skorzystania z usługi ADF, czyli posiadanie subskrypcji Microsoft Azure, utworzenie Azure Data Factory oraz Linked Services, są już spełnione.
1. Wybór źródła danych.
Azure Data Factory pozwala pobierać dane z wielu źródeł. Są wśród nich platformy Azurowe, relacyjne i nierelacyjne bazy danych, serwisy i aplikacje (łącznie ponad 90 tzw. connectors).
2. Utworzenie pipeline-u.
Jest to zasadnicza część procesu ETL. Pipeline jest budowany na bazie tzw. activities, które można porównać do wykonywanych w ramach procesu zadań. Metodą „pociągnij i upuść” są one przenoszone z lewego panelu bocznego do obszaru roboczego. Nowo dodane activities posiadają domyślnie aktywny status, jednak np. w celach testowych możemy go zdezaktywować. W ten sposób dane zadanie zostanie pominięte w procesie, bez konieczności usunięcia go z pipeline-u. Ważnym aspektem tworzenia pipeline-u jest warunkowanie wykonania poszczególnych activities. Przykładowo, posiadając 2 następujące po sobie zadania, możemy w następujący sposób określić relację pomiędzy nimi:
- On Success – kolejna aktywność zostaje wykonana, gdy poprzednia została zakończona sukcesem (symbol zielonej strzałki)
- On Fail – kolejna aktywność zostaje wykonana, gdy poprzednia została zakończona niepowodzeniem (symbol czerwonej strzałki)
- On Completion – kolejna aktywność zostaje wykonana, gdy poprzednia została zakończona- bez znaczenia, z jakim rezultatem (symbol niebieskiej strzałki)
- On Skip – kolejna aktywność zostaje wykonana, gdy poprzednia się nie rozpoczęła (symbol szarej strzałki)
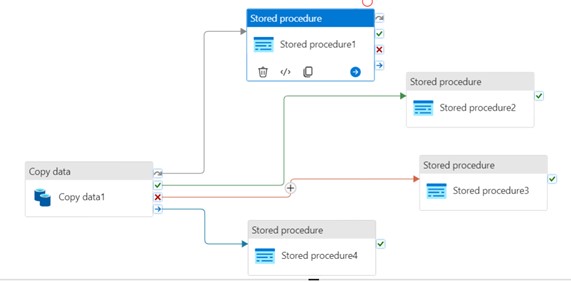
Dzięki powyższej funkcjonalności możemy elastycznie konfigurować alternatywne scenariusze dla utworzonego piepline-u, w zależności od przebiegu konkretnego procesu. Jest to również wygodny sposób obsługi błędów, w przeciwnym razie, aby zastrzec kilka możliwych scenariuszy, musielibyśmy użyć activity If Condition – być może zagnieżdżonej kilkakrotnie, co czyniłoby kod mniej czytelnym, trudniejszym do debugowania i utrzymania.
Po ukończeniu pracy nad pipeline-m, warto użyć opcji Validate, aby sprawdzić, czy pipeline został skonfigurowany poprawnie. Rezultat walidacji będzie widoczny po prawej stronie ekranu, w przypadku braków / błędów, zostaną one wymienione wraz z ich źródłem.
Ostatnim krokiem jest zapisanie pracy za pomocą przycisku Publish All.
3. Uruchomienie pipeline-u.
Istnieje kilka możliwości uruchomienia pipeline-u, które różnią się technicznymi detalami, Można je uogólnić wyróżniając dwie grupy zdarzeń, gdzie start piepline’u może nastąpić:
a) manualnie: poprzez wybór opcji Debug lub Add Trigger – Trigger Now – w ten sposób proces jest uruchamiany w chwili kliknięcia przycisku
b) automatycznie: poprzez wybór opcji Add Trigger – New/Edit , gdzie w zależności od typu triggera -zostaje ustalony harmonogram uruchamiania procesu (data, godzina i częstotliwość) lub uruchomienie procesu zostaje uzależnione od wystąpienia określonego zdarzenia.
4. Śledzenie progresu.
Po uruchomieniu procesu, w panelu u dołu strony, możemy sprawdzać jego progres.
Będziemy widzieć osobny rekord dla każdej aktywności, którą zdefiniowaliśmy. Zadania zakończone sukcesem będą oznaczone standardową, zieloną ikonką, natomiast zakończone błędem – czerwoną. Rekord będzie zawierał również czas wykonania akcji, na co warto zwrócić uwagę w kontekście optymalizacji procesu.
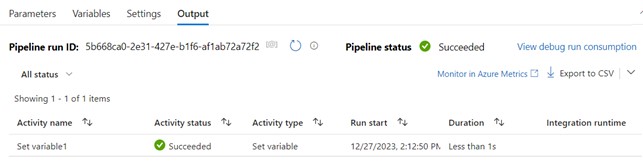
5. Debugowanie błędów (opcjonalnie).
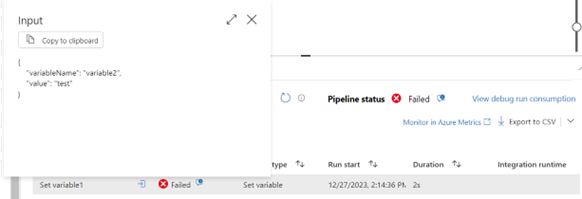
Jeżeli w rezultacie uruchomienia pipeline-u, niektóre zadania zostaną zakończone błędem, możemy sprawdzić jego szczegóły, klikając na dane zadanie. Przykładem prostego błędu może być przypisanie do zmiennej liczbowej wartości tekstowej w ramach zadania Set Variable. Informacja na temat activity zostanie wyświetlona w formacie JSON, gdzie key jest wygenerowany przez ADF, natomiast value reprezentuje wartości podane przez użytkownika.
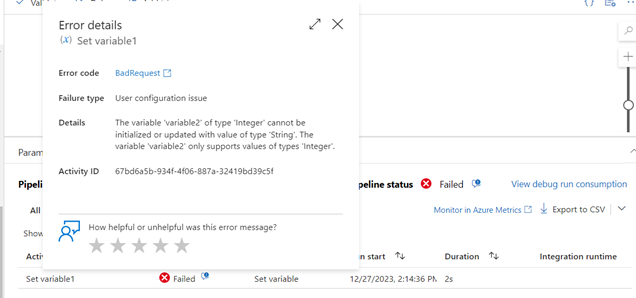
W szczegółach statusu, możemy zobaczyć opis błędu jako zwykły tekst, dzięki czemu możemy skorygować pipeline.
Podsumowując, ADF posiada szeroki wachlarz źródeł oraz możliwości transformacji danych, aby móc tworzyć kompleksowe rozwiązania ETL. Powyżej przedstawiony został krótki przewodnik, jak poruszać się po ADF i na co warto zwrócić uwagę podczas budowania pipeline-u. Dla użytkowników SSMS czy SSIS, praca z ADF powinna być łatwiejsza, gdyż niektóre activities nawiązują do konstrukcji sql-owych np. Filter, If Condition. Znając logikę tych konstrukcji, łatwiej będzie stosować odmienną składnię ADF.
Masz potrzebę utworzenia procesu ETL? Chętnie pomożemy!
















